About SPASE Webserver

SPASE (Soluble Protein Analog Selection Engine)
SPASE is a protein-engineering tool designed to computationally rebuild and optimize protein structures, generating synthetic analogs of an input structure. It can help recovering misfolded proteins, designing synthetic proteins with enhanced stability and folding properties, improving solubility and reducing aggregation, and creating libraries of protein analogs that are more stable and expressible than those generated by other methods.
How does it work?
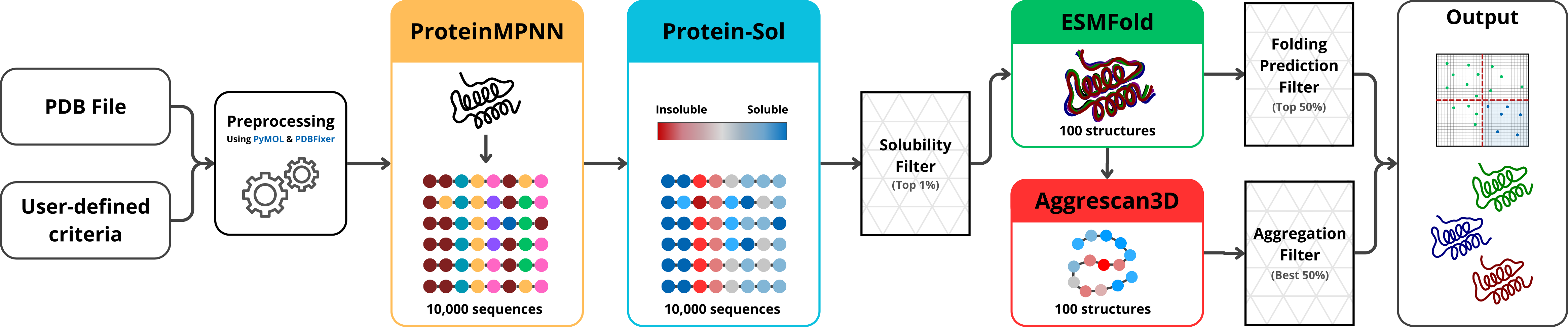
The tool processes an input PDB structure (currently limited to monomers) and generates 10,000 synthetic protein sequences using ProteinMPNN, designed to be structurally analogous to the input. These sequences are optimized to potentially exhibit greater stability, solubility, and reduced aggregation compared to the original. The generated sequences are filtered for solubility using Protein-Sol, prioritizing the most soluble and stable candidates. Their 3D folds are then computationally predicted with ESMFold and scored based on prediction confidence. The top sequences are further screened for aggregation propensity using Aggrescan3D. The final output is a curated list of high-quality protein structures and corresponding sequences suitable for expression and purification for further experimental testing. Additionally, SPASE provides the option to conserve specific amino acid positions critical for function, such as catalytic residues, by fixing them during the generation of sequence analogs.
Here is a high-level overview of the pipeline:
In order to use the SPASE webserver, you need to read the user guide and accept the terms and conditions.
Our team:

Nicolas Doucet, PhD
Principal Investigator

Sacha T. Larda, PhD
Main Developer

Alex Paré, MSc
Main Developer